파이썬을 엑셀처럼 사용하기 시리즈
(2) 데이터 열기 pandas read_excel()
(3) 데이터 정렬하기 pandas sort_values()
(4) 데이터 필터링하기, 비교 연산자 pandas filtering
(7) 피벗 테이블 만들기 pandas pivot_table()
✔ 실습하기 위해서는 파이썬 아나콘다와 주피터 노트북이 설치되어있어야 합니다.
- [파이썬] 파이썬 아나콘다 설치 방법, 파이썬 설치 방법
- [파이썬] 주피터 노트북(jupyter notebook) 사용법
✔ 실습 데이터는 제 깃헙에서 받을 수 있습니다. 데이터1, 데이터2
앞으로 이 시리즈가 끝날 때까지 사용될 엑셀 데이터는 가상의 슈퍼마켓 회사 프로브 마트의 지점 A, B, C의 2019년 1월~3월까지의 매출 데이터입니다. 데이터는 제 깃헙에서 받을 수 있습니다. 링크
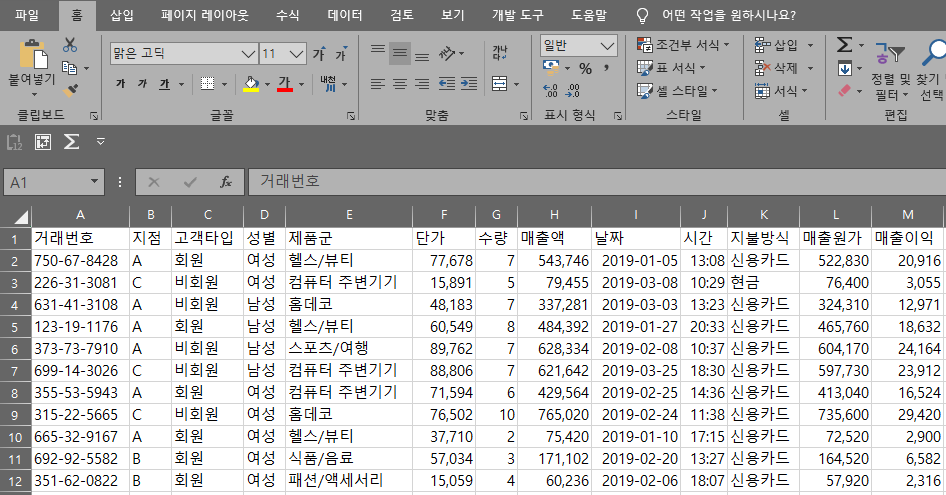
데이터 열기
엑셀의 경우 데이터를 열기 위해서는 해당 파일을 더블 클릭해서 열거나, 엑셀을 실행시킨 다음의 순서대로 파일을 열면 됩니다. [파일 > 열기 > 경로 선택 > 파일 선택]
파이썬의 경우에는 엑셀 파일(xlsx)을 열기 위해서는 판다스 라이브러리를 사용해야 합니다. 판다스 라이브러리란 일종에 확장 프로그램으로 파이썬을 엑셀처럼 사용할 수 있게 도와주는 도구입니다.
판다스 라이브러리를 불러오겠습니다.
import pandas as pd
판다스 라이브러리를 불러와서 pd라는 축약어로 지정합니다. 매번 pandas라는 전체 단어를 타이핑하는 것이 번거로우니 pd라는 짧은 단어 사용하기 위함입니다.
판다스에서 엑셀 파일(xlsx)을 읽으려면 pd.read_excel()를 사용해야 합니다.
sales = pd.read_excel('SupermarketSales.xlsx')
salesSupermarketSales.xlsx라는 엑셀 파일을 읽어와 그 결과를 sales라는 이름의 변수에 저장했습니다. 이제 sales라는 변수를 입력하면 엑셀에서 보는 것과 유사하게 표 형식으로 읽어온 데이터를 화면에서 볼 수 있습니다.

엑셀과 판다스의 몇 가지 차이점
- 엑셀은 행 번호가 1부터 시작하지만 판다스는 0부터 시작합니다.
- 엑셀 파일에 값이 없는 데이터는 판다스에서 Nan(Null)로 표기됩니다.
- 판다스에서 숫자는 기본적으로 모두 실수로 표현되기 때문에 소수점이 있습니다. 설정을 바꿔서 없앨 수 있습니다.
판다스에서는 위와 같은 테이블 형식의 데이터를 데이터프레임이라는 자료구조로 저장합니다. 데이터프레임을 엑셀의 시트와 유사한 개념으로 생각하시면 됩니다. 그리고 이 데이터프레임에서는 행 번호가 있는 부분을 Index라 합니다. (정확히는 행 번호가 아니라 행 데이터의 이름을 나타냅니다.) 또한 각 열 데이터 이름을 Column name이라 합니다.
그림으로 간단히 보면 이렇습니다.
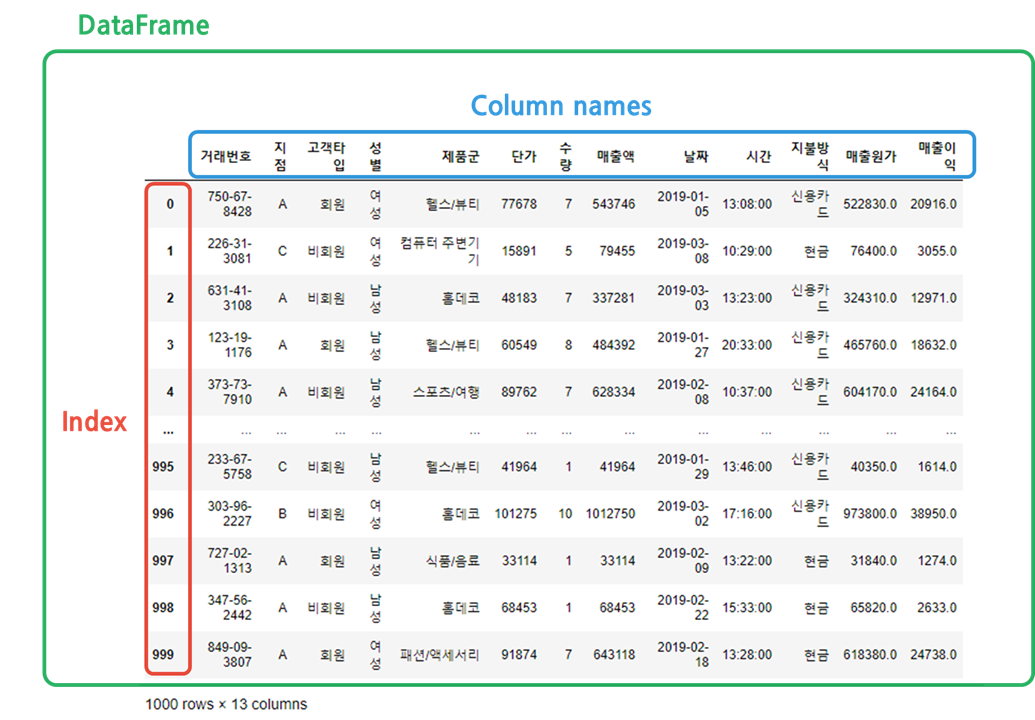
마지막으로 이 sales 변수의 데이터 타입을 확인해보겠습니다.
type(sales)
# >>> pandas.core.frame.DataFrame데이터프레임인 것을 확인했습니다.
다음 시간부터는 데이터프레임이 제공해주는 여러 가지 기능들을 활용하는 방법을 알아보겠습니다. (데이터 정렬 및 필터링, 사칙연산, 피벗 테이블 등)
-이 글은 아나콘다(Anaconda3)가 설치된 환경을 기준으로 작성되었습니다.