긴 문서를 읽다 보면 한 번씩 '아 귀찮다'라는 생각이 듭니다. 누가 와서 간단히 요점만 말해주면 좋을 것 같습니다. 글의 주요 내용을 어떻게 하면 간단히 알아챌 수 있을까요? 이렇게 생각해 볼 수 있을 것 같습니다. 글쓴이는 말하고자 하는 내용을 강조하기 위해 특정 단어들을 더 많이 사용했을 것이다.
이제 남은 일은 단어들이 언급된 빈도를 세어보는 일입니다. 하지만 단어 빈도를 세는 일은 사람이 하기에는 적합한 일이 아닙니다. 컴퓨터가 하기에 적합한 일이죠. 파이썬에게 문서 내의 각 단어의 빈도를 세어달라고 하겠습니다.
이번 글에서는 2020년 대통령 신년사로 빈도 분석을 해보았습니다. 한나눔 형태소 분석기로 명사만을 추출했습니다.
상위 단어를 보면 것(할 것, 될 것, 갈 것 등), 수(할 수, 갈 수 등), 국민, 올해, 노력, 평화와 같은 단어들이 눈에 뜨입니다.
한국어 텍스트 분석을 위한 패키지 KoNLPy
파이썬에는 한국어 처리를 위한 KoNLPy라는 훌륭한 패키지가 있습니다. 설치방법은 링크를 참고해주세요.
[파이썬] 윈도우에 KoNLPy 설치하기: JDK 설치부터 실행까지
라이브러리 임포트
from konlpy.tag import Hannanum
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
대통령 신년사 스크래핑
- css selector를 이용해서 간단히 본문 내용만 추출할 수 있습니다.
- cs_body를 기준으로 자손 태그까지 타고 내려갑니다.

url = 'https://www1.president.go.kr/articles/7940'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'html.parser')
text = soup.select_one('.cs_body > .cs_view.text > .text')
text = text.get_text(' ', strip=True)
text
텍스트 정리하기
- 단어의 빈도 계산과 별 상관이 없는 문자들을 걸러내려고 합니다. 숫자, 문장부호, 특수문자 등을 제거합니다.
text = re.sub('[0-9]+', '', text)
text = re.sub('[A-Za-z]+', '', text)
text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ·!』\\‘’|\(\)\[\]\<\>`\'…》]', '', text)
형태소 분석기 사용하기
hannanum = Hannanum()
text_list = hannanum.nouns(text)
text_list
# >>> ['존경', '국민', '여러분', ..., '우리', '삶']
판다스 Series를 이용해서 명사 빈도 세기
- 판다스에는 value_counts()라는 유용한 메서드가 있습니다. 이 메서드를 사용하면 각각의 고유 값(unique value)의 개수를 반환합니다.
word_list = pd.Series(text_list)
result = word_list.value_counts().head(20)
result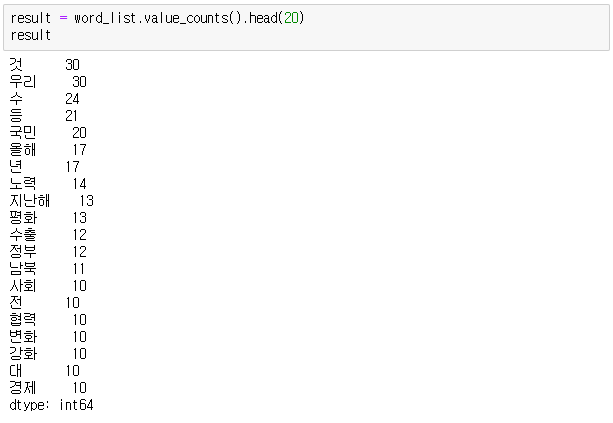
- 이 글의 코드는 아나콘다(Anaconda3)가 설치된 주피터 노트북에서 작성되었습니다.