파이썬에서 Selenium을 이용해서 웹크롤링을 한다면 대개 다음과 같은 코드를 씁니다.
# 라이브러리 불러오기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
# 특정 웹페이지에 접근하기
driver = webdriver.Chrome()
driver.get("웹페이지 주소")
driver.implicitly_wait(10)
# HTML 코드 가져오기
r = driver.page_source
# 파싱
soup = BeautifulSoup(r, "html.parser")
# 이후 데이터 수집 작업
대부분의 웹페이지는 이것으로 충분합니다. 하지만 만약 지금 내가 접근한 웹페이지에서 수집하고 싶은 데이터가 iframe 요소 안에 있다면 얘기가 달라집니다. iframe 요소를 이용해서 페이지 안에 페이지를 삽입한 형태이기 때문입니다. 예를 들어 네이버 카페의 게시판 부분이 iframe 요소로 구성되어있습니다.
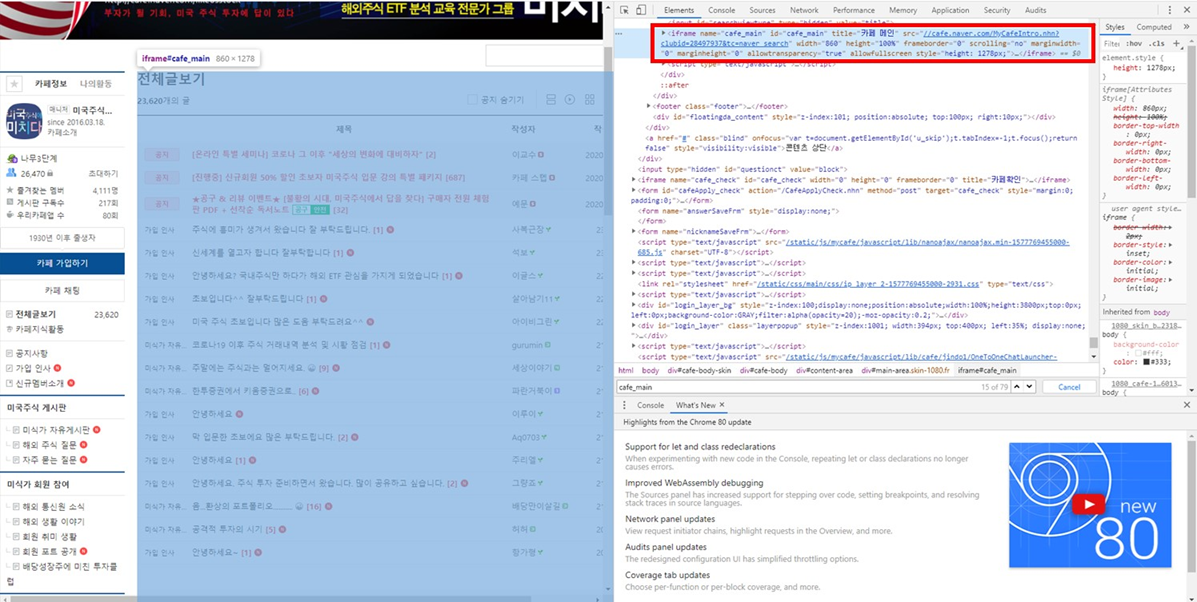
iframe 요소 가져오는 방법
iframe 페이지로 전환하기 위해서는 다음의 코드가 필요합니다.
driver.switch_to.frame("id 또는 name")
네이버 카페 게시판을 크롤링하는 예제 코드를 보겠습니다. 로그인, 카페 가입, 등급 등의 조건은 이미 만족되어 있다고 가정하겠습니다. 네이버 로그인 방법은 링크를 참고해주세요.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get("카페 주소")
driver.implicitly_wait(10)
"""
검색, 게시판 이동 등의 동작을 나타내는 코드 작성
"""
driver.switch_to.frame("cafe_main")
r = driver.page_source
soup = BeautifulSoup(r, "html.parser")
위의 코드처럼 원하는 페이지로 이동한 다음 iframe 페이지로 전환하면, 그 부분의 HTML 코드를 가져올 수 있습니다. 여러 페이지에서 정보를 수집할 거라면 페이지를 이동할 때마다 iframe 페이지로 전환해줘야 합니다.
- 이 글은 아나콘다(Anaconda3)가 설치된 주피터 노트북에서 작성되었습니다.